
AutoFigure:生成可编辑的科研插图
AutoFigure 将论文方法文本转化为完全可编辑的 SVG 科研插图 —— 可自由修改的出版级学术配图。
结合 LLM 生成、SAM3 分割和矢量化技术,AutoFigure 生成高质量方法论图表,支持从参考图像进行风格迁移,并内置浏览器端 SVG 编辑器进行实时调整。
立即体验 AutoFigure
亲身体验 AutoFigure 的自动化论文配图生成能力。粘贴你的方法文本,可选上传参考图像进行风格迁移,AutoFigure 即可生成出版级的可编辑 SVG 科研插图。支持方法论图表、系统架构图、流程图等多种类型,全部输出为可自由编辑的矢量图形。
提示:简洁、结构化的方法文本能生成更清晰的模板
提示:上传您喜欢的论文配图以迁移其视觉风格
没有生成图片
AutoFigure 示例展示
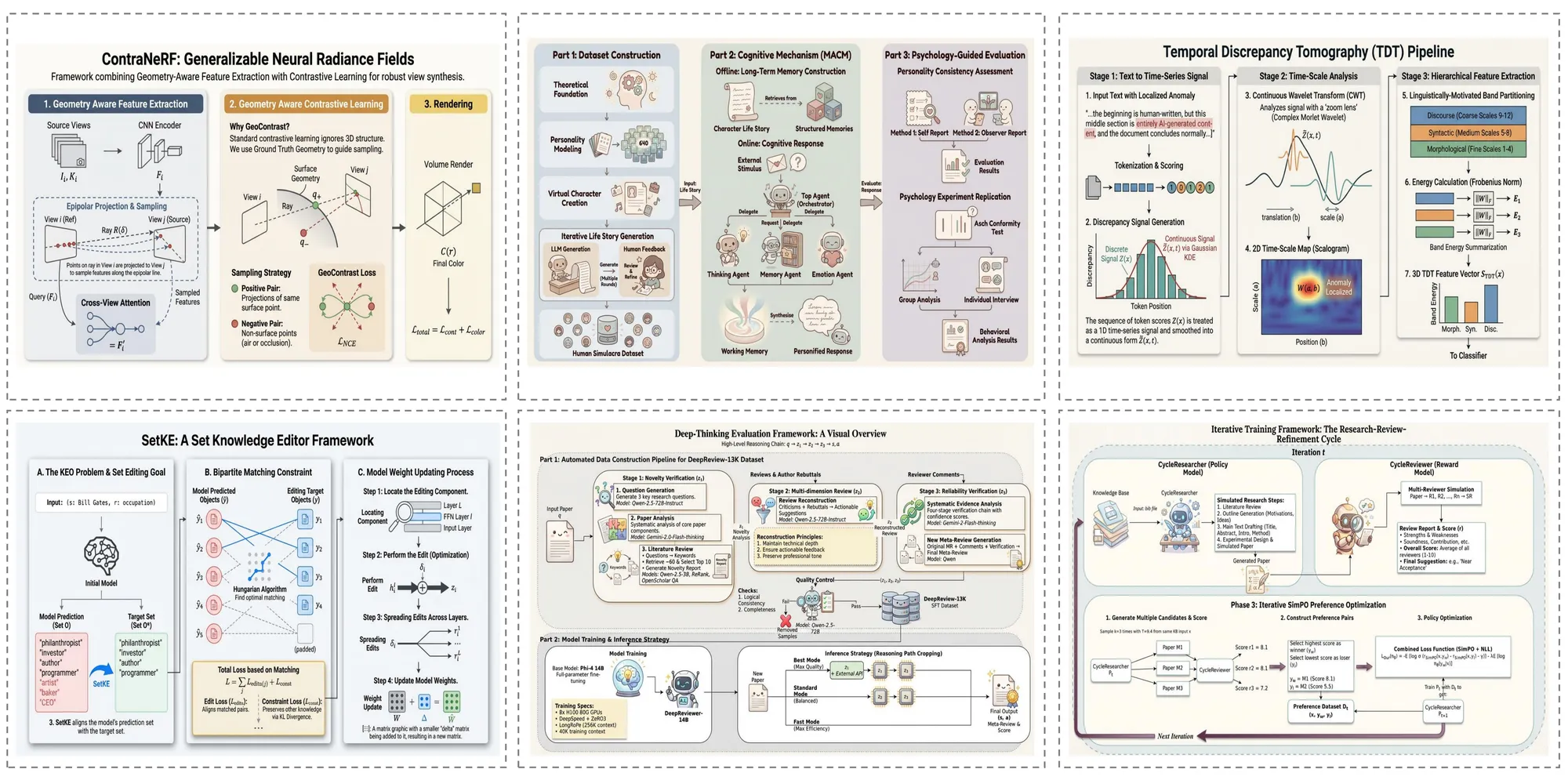
以下是 AutoFigure 在不同领域生成的示例图表,展示了其处理各种复杂度科研插图的多样化能力。
论文案例
AutoFigure 直接从研究论文文本生成出版级的方法论图表。复杂的模型架构、多阶段流水线和编码器-解码器框架被渲染为完全可编辑的 SVG 插图,包含精确的形状、连接线和标签 —— 可直接用于顶会投稿。
综述案例
对于综述论文,AutoFigure 创建全面的概览图,捕捉多种方法之间的分类体系、关系和对比。生成的图表帮助读者通过清晰的视觉层次和一致的样式快速把握研究领域的全貌。
博客案例
AutoFigure 同样能处理非正式的技术写作。从解释机器学习概念的博客文章到技术教程,它生成清晰且视觉吸引力强的图表,让复杂的想法对更广泛的受众易于理解。
教材案例
对于教育内容,AutoFigure 生成教材级质量的插图,清晰传达基础概念。无论是神经网络架构、数据流图还是生物过程,生成的图表都适用于课件幻灯片、课程材料和教材章节。
常见问题
关于 AutoFigure 的常见问题与解答。
Auto Figure 的核心创新
AutoFigure-Edit 在自动化科研插图生成领域引入了多项突破性创新,发表于 ICLR 2026。
系统架构:五阶段流水线
Auto Figure 通过五阶段流水线将科学文本转化为可编辑的 SVG 插图。每个阶段在前一阶段的基础上构建,逐步将原始文本转化为完全可编辑的、出版级矢量插图。
阶段一:栅格生成
视觉语言模型(Gemini 3.1 Flash)读取方法文本和可选的参考图像,生成初始栅格草稿(figure.png)。LLM 理解科研图表的惯例,将文本方法论转译为视觉构图。
阶段二:SAM3 分割
Segment Anything Model 3(SAM3)使用结构化提示词(如 'icon, person, robot, animal')检测和分割各独立组件——图标、文字区域、连接线、形状。输出带置信度评分的边界框和分割图(samed.png)。
阶段三:SVG 模板化
以原始图像、分割掩码和边界框元数据作为多模态输入,LLM(Gemini 3.1 Pro)生成占位符风格的 SVG,其边框与标记区域对齐。RMBG-2.0 去除裁剪图标的背景,创建透明素材。
阶段四:最终组装
系统对齐 SVG 模板和原始图像之间的坐标系统,然后用从分割中提取的透明图标替换占位符。生成的组装 SVG(final.svg)中所有组件都是可独立编辑的矢量元素。
阶段五:迭代优化
可选的优化阶段执行迭代 SVG 精修——路径优化、笔画识别和布局微调。用户还可以在 Auto Figure 内置的 svg-edit 画布中通过拖放组合进行精修,完成从文本到可编辑 SVG 的完整工作流。
分享 AutoFigure